Small business lending has undergone a dramatic digital transformation with digital platforms, embedded finance ecosystems, and automated credit underwriting. However, the rapid digital transformation has also increased exposure to sophisticated fraud schemes.
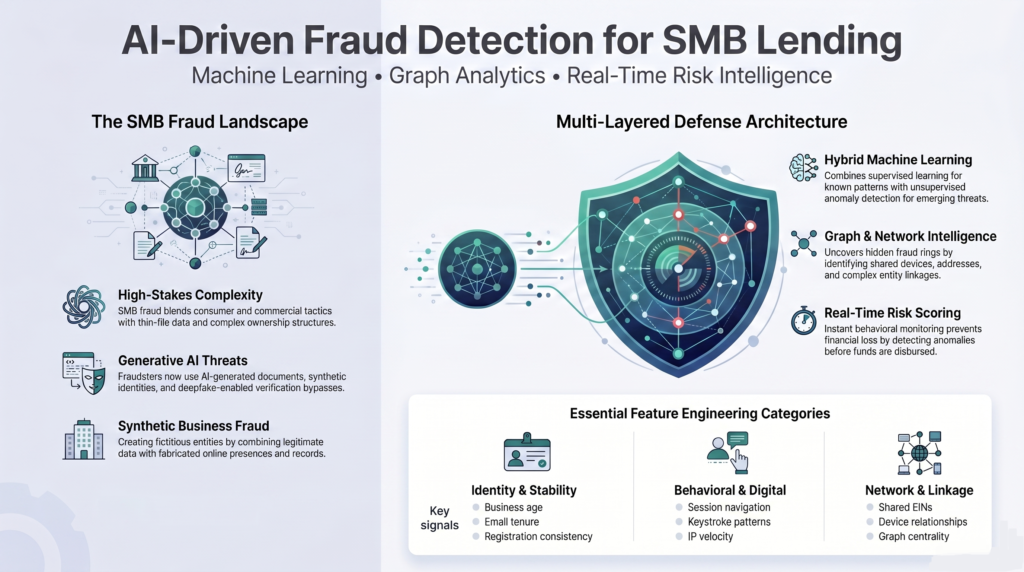
The rise of generative AI has lately amplified these risks even further. AI-generated documents, synthetic identities, and deepfake-enabled verification bypasses are increasing rapidly across financial services fraud ecosystems.
Building effective defense against fraud in SME lending requires more than a generic and traditional rules-based engine or static verification checks. Fraud prevention requires a process-centric, multi-layered machine learning framework powered by robust data pipelines, behavioral analytics, graph-based relationships, and real-time decisioning.
Fraud Risk is Different in SMB Lending
Small business lending presents unique fraud detection challenges compared to traditional consumer lending. Unlike consumer credit, SMB lending often involves:
- Thin-file businesses and limited audited financial data
- Rapidly changing cash flow patterns
- Informal ownership structures and multiple linked entities
- Higher document dependency with stringent underwriting timelines
Additionally, in small business lending, fraud frequently combines characteristics of both consumer and commercial fraud.
Common Types of Fraud in SMB Lending
Before building fraud models, organizations must define the fraud taxonomy they intend to detect. Common fraud categories include:
1. Synthetic Business Fraud
Fraudsters create fictitious or partially synthetic businesses by combining legitimate and fabricated information. These businesses may:
- Use stolen identities
- Recycle addresses or phone numbers
- Fabricate an online presence
- Manipulate business registration records
- Establish fake vendor relationships
Synthetic business fraud presents a growing concern because commercial lending often involves larger dollar exposures than consumer lending.
2. Identity Fraud
This involves stolen or impersonated identities used to obtain financing. Examples include:
- Stolen SSNs
- Compromised business owner identities
- Fake beneficial owners
- Deepfake-assisted identity verification attacks
- Business identity theft
3. First-Party Fraud
Applicants intentionally misrepresent information while intending to default. Examples:
- Inflated revenue
- Misrepresented business age
- Fabricated invoices
- False payroll data
- Strategic defaults
4. Application Fraud
Fraudulent applications may involve manipulated financial documents, fabricated businesses, or coordinated fraud rings.
5. Account Takeover Fraud
Existing borrower accounts are compromised through credential theft or social engineering.
6. Bust-Out Fraud
Fraudsters establish legitimate-looking payment histories before drawing down large balances and disappearing.
Core Principles of Fraud Model Development
An effective fraud detection model requires a lot more than high modeling accuracy. Fraud modeling frameworks should optimize simultaneously across multiple dimensions, such as:
- Fraud capture rate
- False positive reduction
- Real-time decision speed
- Operational scalability
- Explainability
- Adaptability to evolving fraud patterns
- Regulatory compliance
Fraud models must also function within an adversarial environment. Unlike credit risk models, where borrower behavior is relatively stable and predictable, fraudsters continuously adapt to detection strategies. This means fraud models require ongoing recalibration, retraining, and monitoring.
Fraud Modeling Methodology
Step 1: Define the Fraud Target
The first step is establishing clear fraud definitions. Organizations must determine:
- What constitutes confirmed fraud
- What is suspected fraud
- What observation windows should be used
- How will labels be generated
- What operational outcomes matter most
Fraud labeling is often one of the most difficult challenges because:
- Confirmed fraud may take months to materialize
- Operational investigations can be inconsistent
- Charge-offs may contain mixed risk signals
- Some fraud is never discovered
Strong governance around fraud labeling is essential for model reliability.
Step 2: Data Collection and Integration
Fraud models are only as strong as the underlying data architecture. The most effective fraud platforms integrate data from multiple internal and external sources. Key data sources for SMB fraud models include:
1. Application Data
Core onboarding attributes include:
- Business name
- EIN
- Industry classification
- Time in business
- Revenue
- Ownership structure
- Beneficial owner information
- Address history
- Phone numbers
- Email domains
Application inconsistencies are often strong indicators of fraud. Such as:
- High revenue with newly established businesses
- Disposable email domains
- Mismatched business classifications
- Suspicious business naming patterns
2. Credit Bureau Data
Both consumer and commercial bureau data provide valuable fraud signals. Examples include:
- Thin-file behavior
- Velocity of recent inquiries
- Address mismatches
- Tradeline inconsistencies
- Identity anomalies
- Credit header instability
Commercial bureau data can also reveal:
- UCC filings
- Corporate linkage structures
- Historical delinquencies
- Related entities
3. Bank Transaction Data
Bank transaction analytics have become one of the most powerful fraud detection tools in modern lending. Open banking integrations and cash-flow underwriting platforms provide highly granular transactional insights. Key fraud indicators include:
- Revenue volatility
- Circular transactions
- Rapid inflow/outflow patterns
- Synthetic payroll behavior
- Unusual ACH activity
- Merchant concentration anomalies
- Excessive NSF activity
- Recently opened bank accounts
Transaction-level behavioral analysis is often more predictive than static application attributes.
4. Device and Digital Identity Data
Digital identity intelligence has become increasingly important in online lending. Common signals include:
- Device fingerprints
- IP geolocation
- VPN usage
- Emulator detection
- Browser configurations
- Session velocity
- Behavioral biometrics
- Keystroke patterns
Behavioral anomalies frequently expose synthetic identities even when traditional KYC checks appear clean.
5. Consortium and Network Data
Fraud rings often reuse information across institutions. Consortium data enables lenders to detect:
- Shared devices
- Shared phone numbers
- Shared addresses
- Shared bank accounts
- Cross-lender fraud activity
Graph-based fraud detection has become especially valuable in uncovering organized fraud networks.
6. Public and Alternative Data
Alternative data sources can enhance fraud detection coverage. Examples include:
- Secretary of State filings
- Business registrations
- Website age
- Online reviews
- Social media presence
- Utility records
- Geospatial data
- Business licensing records
A business claiming millions in annual revenue but having no digital footprint may represent elevated fraud risk.
Feature Engineering for Fraud Detection
Feature engineering is often the most critical component of fraud model performance. Sophisticated fraud detection relies heavily on engineered behavioral and relational variables.
Common Feature Categories
1. Identity Stability Features
Examples:
- Time since SSN issuance
- Address stability
- Phone tenure
- Email age
- Business registration age
2. Velocity Features
Examples:
- Number of applications in last 24 hours
- Device reuse counts
- IP velocity metrics
- Inquiry frequency
3. Consistency Features
Examples:
- Revenue-to-industry comparisons
- Payroll-to-revenue ratios
- Address consistency across sources
- Cash-flow consistency checks
4. Behavioral Features
Examples:
- Mouse movement patterns
- Time spent completing application
- Copy/paste behavior
- Session navigation patterns
5. Network Features
Examples:
- Shared entity linkages
- Device relationship scores
- Fraud ring connectivity metrics
- Graph centrality measures
Graph analytics are becoming increasingly important because fraud rarely occurs in isolation.
Machine Learning Approaches for Fraud Detection
Fraud detection typically requires a layered modeling framework rather than a single algorithm.
1. Rules Engines
Rules remain important for:
- Regulatory requirements
- Hard-stop controls
- Explainability
- Known fraud patterns
Examples:
- Block known fraudulent devices
- Flag impossible geographies
- Identify prohibited industries
However, rules alone are insufficient because fraud evolves rapidly.
2. Supervised Machine Learning Models
Supervised learning remains the foundation of many fraud detection systems.
Common algorithms include:
- Gradient boosting machines (XGBoost, lightGBM)
- Random forests
- Logistic regression
- Neural networks
- Ensemble models
These models learn historical fraud patterns from labeled datasets.
Key modeling considerations include:
- Class imbalance handling
- Precision vs recall optimization
- Cost-sensitive learning
- Threshold calibration
- Time-based validation
Fraud datasets are often highly imbalanced because fraudulent applications represent a small percentage of the total volume. Therefore, model evaluation should focus on:
- Precision and Recall
- PR-AUC
- Fraud capture rates
- Financial loss reduction
rather than simple accuracy metrics.
3. Unsupervised and Anomaly Detection Models
Many fraud patterns are previously unseen. Unsupervised approaches help identify anomalies without historical labels.
Examples include:
- Autoencoders
- Isolation forests
- Clustering models
- Density-based detection
These methods are especially useful for:
- Modern and emerging fraud attacks
- Novel synthetic identities
- Unknown fraud rings
4. Graph-Based Fraud Detection
Graph-based models are becoming increasingly important in financial crime detection. Fraud entities rarely operate independently. Graph models help identify:
- Shared infrastructure
- Coordinated fraud rings
- Hidden relationships
- Entity networks
Examples of graph relationships:
- Shared devices
- Shared addresses
- Shared EINs
- Shared bank accounts
- Shared phone numbers
- Shared IP addresses
Graph neural networks and link analysis techniques uncover hidden fraud structures that traditional models miss.
5. Real-Time Streaming Models
Modern digital lending platforms require real-time fraud decisioning. Streaming architectures enable:
- Instant fraud scoring
- Dynamic behavioral monitoring
- Continuous risk updates
- Adaptive authentication
Real-time systems often combine:
- Feature stores
- Streaming pipelines
- Event-driven architectures
- API-based scoring
6. Behavioral Biometrics
Behavioral identity is becoming a critical defense layer. Patterns such as:
- Typing cadence
- Mouse dynamics
- Device interactions
- Session behaviors
can help distinguish legitimate borrowers from automated or synthetic actors.
7. Graph AI and Network Intelligence
Graph-based detection is becoming a major competitive differentiator. Modern fraud systems increasingly analyze entire ecosystems rather than isolated applications.
This shift is especially important in SMB lending, where shell entities and synthetic businesses often operate in coordinated networks.
8. Agentic AI for Fraud Operations
AI-assisted investigation frameworks are beginning to automate portions of fraud operations workflows. Emerging architectures combine:
- LLM-based reasoning
- Document analysis
- Evidence collection
- Case summarization
- Workflow orchestration
to improve analyst productivity and reduce alert fatigue.
Fraud Model Architecture
High-performing fraud platforms typically use a multi-layered architecture. A common framework may include:
Layer 1: Identity Verification
- KYC checks
- Document verification
- Liveness detection
- Identity resolution
Layer 2: Rules and Policy Engine
- Hard-stop rules
- Velocity checks
- Geographic restrictions
Layer 3: Machine Learning Scoring
- Fraud probability scoring
- Ensemble models
- Behavioral scoring
Layer 4: Network and Graph Analytics
- Fraud ring detection
- Shared entity analysis
- Relationship scoring
Layer 5: Real-Time Decisioning
- Fraud prevention becomes dramatically harder after funds are disbursed. Real-time scoring is essential.
Layer 6: Model Monitoring and Drift Management
Fraud patterns evolve continuously. A fraud model that performs well today may degrade rapidly as fraudsters adapt. Continuous monitoring should include:
- Population stability monitoring
- Feature drift analysis
- Precision/recall tracking
- Fraud capture degradation
- Operational review outcomes
- Latency monitoring
Leading organizations retrain fraud models frequently and maintain adaptive feedback loops between fraud operations and modeling teams.
Layer 7: Cross-Functional Collaboration and Learning
Fraud models should incorporate investigator feedback and operational outcomes. These include:
- Case management
- Analyst review
- Escalation workflows
The goal is not simply automation. The goal is intelligent orchestration between machine intelligence and human expertise. Effective fraud programs require collaboration between data science, operations, risk management, compliance, and product teams.
Layer 8: Explainability and Regulatory Considerations
Fraud models in lending environments must balance predictive power with explainability. Regulators increasingly expect:
- Transparent decisioning
- Model governance
- Fair lending compliance
- Bias monitoring
- Auditability
Thus, organizations need to establish:
- Model validation frameworks
- Champion/challenger testing
- Feature governance
- Drift monitoring
- Adverse action review processes
Explainable AI techniques such as SHAP values and interpretable surrogate models can improve operational transparency.
Building Fraud-Resilient Lending Ecosystem
Building effective fraud detection models for small business lending requires deep expertise in machine learning, data engineering, fraud operations, and lending risk management.
Traditional rule-based systems alone are no longer sufficient in an environment increasingly shaped by:
- Synthetic identities
- AI-generated documents
- Coordinated fraud rings
- Automated attack strategies
- Rapidly evolving fraud tactics
Modern fraud prevention requires layered intelligence powered by:
- Advanced analytics
- Graph-based modeling
- Behavioral monitoring
- Real-time scoring architectures
- Continuous model adaptation
Lenders that invest in adaptive fraud intelligence reduce losses, improve operational efficiency, and create safer digital lending experiences while continuing to grow approvals for legitimate businesses.
Ready to strengthen your small business lending fraud prevention strategy?
Connect with us to learn how custom fraud modeling solutions can help your organization build scalable, intelligent, and fraud-resilient lending operations.